kafka的安装与配置教程
一、Kafka介绍
Kafka是Apache旗下的一款分布式消息中间件。消息中间件可以将生产者生产出的数据放在一个消息队列中,等待后端消费者来消费处理。除了处理速度比数据库快的优势外,消息队列后还可以避免生产者或者消费者任意一方出现问题时发生数据丢失的情况。所以在业务高峰期的时候,可以将一些数据放在消息队列中,等待系统慢慢消费处理,实现削峰。如果消息队列满了可以考虑对消息队列服务进行扩容。
为了避免Kafka数据丢失或者数据重复带来的数据不一致性问题,需要服务端、客户端都做好相应配置以及采取一些补偿方案:
· 生产端:不少生产消息。比如使用带回调方法的API来确认消息发送是否成功、生产消息有重试机制等
· 服务端:不丢失消息。比如对副本做好相关配置。
· 消费端:不少消费消息。
二、Kafka相关名词解释
· broker:kafka集群由多个节点构成,每个节点上的实例就叫做broker
· producer:生产者,由它来生产数据和决定消息的属性,比如partition和replicas的数量。kafka配置文件中虽然也可以指定,但那个只是默认值
· consumer:消费者,由它来处理生产出的数据,将消费进度offset保存在Kafka的topic中
· topic:主题,起到数据分类的作用
· partition:分区,每个topic可以有多个分区。合理的分区可以提高Kafka集群的负载能力
· replicas:副本,每个partition可以配置多个replicas作为备份。在这些副本中会有一个leader角色负责数据的读写操作,而其他副本则属于follower,仅和leader保持同步而不提供其他服务。当leader故障时,Kafka根据ISR(将所有follower加入到ISR中,如果有follower迟迟不能和leader保持同步则将其踢出)选取一个follower提升为leader。这些副本之间存在一个同样的高水位(High Watermark),高水位的作用就是让消费者只能看到水位线之前的数据,这样可以确保角色切换后对于消费者来说数据是一致的,但是不能保证数据的完整或者不重复。数据的丢失或者重复问题由ACK机制负责,ACK级别分了0、1、-1三种,0、1均有丢失数据的问题,-1代表leader和follower全部落盘成功后才返回ack,数据不会丢失,但可能产生重复数据。
· zookeeper:注册中心服务。由于kafka支持集群化,leader和follower可能不在一个服务器中,这个时候就需要将leader的信息注册在Zookeeper中。对于Kafka而言,它将每个节点信息的运行情况告诉zk,再由zk来配置和存储节点与主题队列信息。zk和kafka的topic有一样的leader\follower角色
三、搭建Zookeeper+Kafka集群
1、由于Kafka是一个分布式系统,它依赖ZooKeeper来完成协调任务、状态与配置管理,所以在运行Kafka之前要先安装并启动ZK
2、下载并安装kafka
[root@localhost ~]# wget https://mirrors.aliyun.com/apache/kafka/2.8.1/kafka_2.13-2.8.1.tgz
[root@localhost ~]# tar xf kafka_2.13-2.8.1.tgz
[root@localhost ~]# mv kafka_2.13-2.8.1 /usr/local/kafka3、修改kafka配置文件
[root@localhost ~]# mv kafka_2.13-2.8.1 /usr/local/kafka
[root@localhost ~]# cd /usr/local/kafka/
[root@localhost kafka]# vim config/server.properties
# 使用grep进行过滤下
[root@localhost kafka]# cat config/server.properties | grep -v '^$'|grep -v '^#'
broker.id=0
listeners = PLAINTEXT://10.2.4.248:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.flush.interval.ms=10000
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=10.2.4.248:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
4、kafka启动
[root@localhost kafka]# /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties查看启动进程
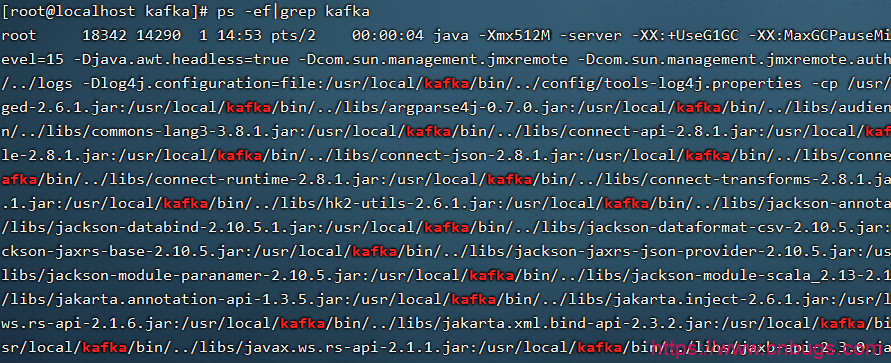
5、登录zookeeper查看是否有kafka信息注册进来
[root@localhost kafka]# /usr/local/zookeeper/bin/zkCli.sh

6、创建topic,完成数据的生产与消费
[root@localhost kafka]# /usr/local/kafka/bin/kafka-topics.sh --create --zookeeper 10.2.4.248:2181 --replication-factor 1 --partitions 1 --topic test
Created topic test.
#--zookeeper:如果ZK是集群的话,随便写一个地址都可以
#--replication-factor:topic的副本数,通常3节点的话2个副本就够了,而1其实代表没有副本
#--partitions:topic分区的数量,通常和节点数保持一致
#--topic:队列名字
查看topic
[root@localhost kafka]# /usr/local/kafka/bin/kafka-topics.sh --list --zookeeper 10.2.4.248:2181
test查看topic详细信息,包含分区、副本与Leader情况
[root@localhost kafka]# /usr/local/kafka/bin/kafka-topics.sh --describe --topic test --zookeeper 10.2.4.248:2181
Topic: test TopicId: tLEtT_J_TY-7Rn0btiKtmQ PartitionCount: 1 ReplicationFactor: 1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0删除topic
[root@localhost kafka]# /usr/local/kafka/bin/kafka-topics.sh --zookeeper 10.2.4.248:2181 --delete --topic test
Topic test is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
在2个终端下分别使用下面的脚本模拟数据生产与消费过程
##在hello这个队列中开始生产数据
[root@localhost kafka]# /usr/local/kafka/bin/kafka-console-producer.sh --broker-list 10.2.4.248:9092 --topic hello
>1
##从队列头部开始消费数据
[root@localhost ~]# /usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server 10.2.4.248:9092 --topic hello --from-beginning
1登录zookeeper进行验证
[root@localhost kafka]# /usr/local/zookeeper/bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /brokers
[ids, seqid, topics]
[zk: localhost:2181(CONNECTED) 1] ls /brokers/topics
[__consumer_offsets, hello]
Kafka的扩容
1、首先要明白扩容的话意味着需要增加Kafka节点,所以第一件事就是在新节点上部署好Kafka,配置要和之前节点一致
2、登录ZK节点然后查看ids信息,如果发现新节点代表Kafka扩容是成功的
3、列出所有topic,找到需要扩容的topic,假设这里的topic是test
./kafka-topics.sh --list --zookeeper 192.168.1.101:2181./kafka-topics.sh --describe --zookeeper 192.168.1.101:2181/kafka --topic test #可以看到test的partition和replicase等信息4、 对partition进行扩容,扩容后重新查看信息可以看到变化,但是这个时候replicas依然只有一份
./kafka-topics.sh --zookeeper 192.168.1.101:2181/kafka --alter --topic test --partitions 3 #扩充到3个partitions5、replicas的扩容需要先生成json文件,然后再用命令去读取该文件。需要注意如果该文件以前给其他topic使用过,需要重新生成一份而不能直接在上面修改,否则会失败
vi test.json
{
"partitions": [
{
"topic": "test", #需要扩容的topic
"partition": 0, #需要增加replicas的partitons
"replicas": [ #replicas需要增加在哪个broker.id上
34,
35
]
},
{
"topic": "test",
"partition": 1,
"replicas": [
34,
35,
36
]
}
]
}6、通过json文件扩容Replicas
./kafka-reassign-partitions.sh --zookeeper 192.168.1.101:2181/kafka --reassignment-json-file test.json --execute 7、最后查看topic信息
./kafka-topics.sh --describe --zookeeper 192.168.1.101:2181/kafka --topic test



![Salt Master报错:Minion did not return. [No response]](https://www.cnbugs.com/wp-content/uploads/2022/08/1660014164-78805a221a988e7.png)