HDFS文件的写入流程
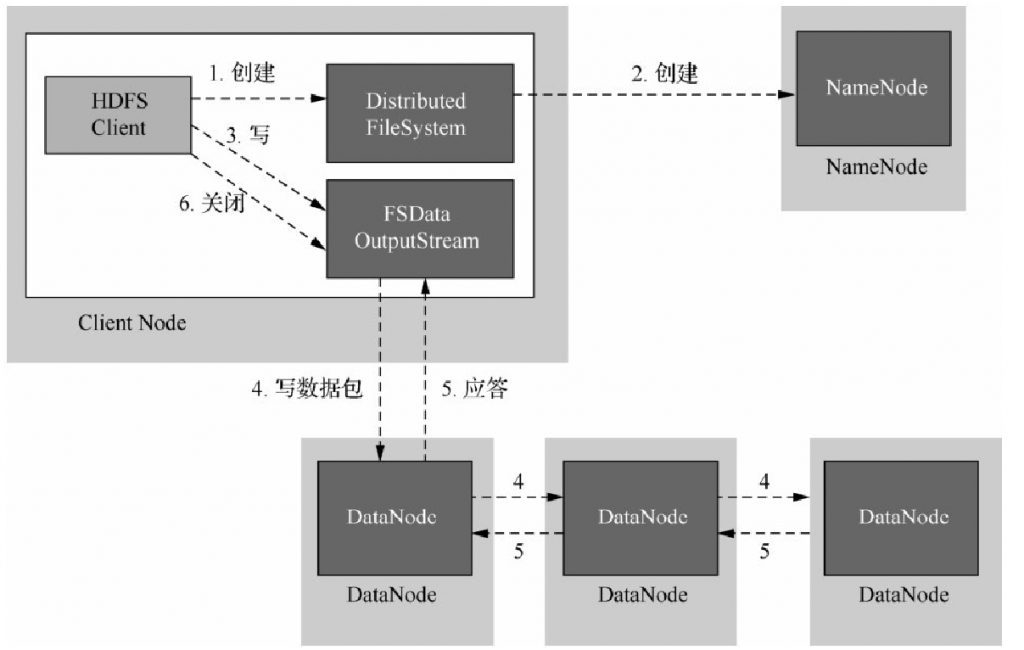
(1)客户端调用DistributedFileSystem对象create()函数创建文件。
(2)DistributedFileSystem对NameNode进行RPC调用,在文件系统的命名空间中新建一个文件,但没有相应的数据块与文件关联,即还没有相关的DataNode与之关联.
(3)NameNode会执行相关的检查以确保文件系统中不存在该文件,并确认客户端有创建文件的权限。当所有验证通过后,NameNode会创建一个新文件的记录,否则,文件创建失败并向客户端抛出一个IOException异常。如果创建成功,则DistributedFileSystem向客户端返回一个FSDataOutputStream对象,客户端使用该对象向HDFS写入数据,同样地,FSDataOutputStream封装着一个DFSOutPutStream数据流对象,负责处理NameNode和DataNode之间的通信。
(4)当客户端写入数据时,DFSOut Put Stream会将文件分割成多个数据包,并写入一个数据队列中。Data Streamer负责处理数据队列,会将这些数据包放入到数据流中,并向NameNode请求为新的文件分配合适的DataNode存放副本,返回的DataNode列表形成一个管道,假设副本数为3,那么管道中就会有三个DataNode,Data Streamer将数据包以流的方式传送给队列中的第一个DataNode,第一个DataNode会存储这个数据包,然后将它推送到第二个DataNode中,然后第二个DataNode存储该数据包并且推送给管道中的第三个DataNode。
(5)DFSOutputStream同时维护着一个内部数据包队列来等待DataNode返回确认信息,被称为确认队列。只有当管道中所有的DataNode都返回了写入成功的信息后,该数据包才会从确认队列中删除。
(6)客户端成功完成数据写入操作以后,对数据流调用close()函数,该操作将剩余的所有数据包写入DataNode管道,并连接NameNode节点,等待通知确认信息。
如果在数据写入期间DataNode发送故障,HDFS就会执行以下操作。
①首先关闭管道,任何在确认队列中的数据包都会被添加到数据队列的前端,以保证管道中失败的DataNode的数据包不会丢失。当前存放在正常工作的DataNode上的数据块会被制定一个新的标识,并和NameNode进行关联,以便故障DataNode在恢复后可以删除存储的部分数据块。
②然后,管道会把失败的DataNode删除,文件会继续被写到另外两个DataNode中。
③最后,NameNode会注意到现在的数据块副本没有达到配置属性要求,会在另外的DataNode上重新安排创建一个副本,后续的数据块继续正常接收处理。