centos7单机部署Spark服务
Spark 虽然是大规模的计算框架,但也支持在单机上运行,这里的教程提供的是单机模式安装。
Spark 安装非常简单,简单到只需要下载 binary 包解压即可,具体的步骤如下。
一、安装前准备
安装 Spark 之前需要先安装 Java,Scala 及 Python。
1.1 安装 Java
首先我们创建hadoop用户并切换到 hadoop 用户下:
[root@cnbugs ~]# useradd hadoop
[root@cnbugs ~]# su - hadoop查看java版本

java安装过程不在多说,可以在我其他文章中查找,下面附上java SE JDK下载链接
http://www.oracle.com/technetwork/java/javase/downloads/index.html1.2 安装 Scala
[hadoop@cnbugs ~]$ wget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz
[hadoop@cnbugs ~]$ tar xf scala-2.11.8.tgz 添加scala系统变量
[hadoop@cnbugs ~]$ vim .bashrc
export SCALA_HOME=/home/hadoop/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin[hadoop@cnbugs ~]$ source .bashrc2、 安装python
一般情况下系统会自动安装好python
查看当前python版本

二、Spark安装
官网上下载已经预编译好的 Spark binary,直接解压即可。
Spark官方下载链接
http://spark.apache.org/downloads.html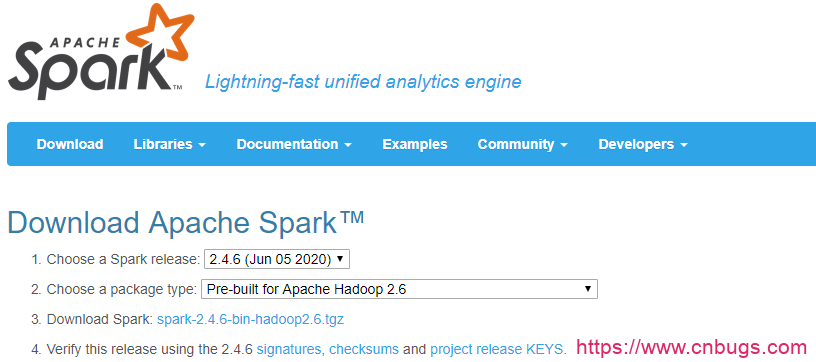
下载Spark的安装包
[hadoop@cnbugs ~]$ wget https://mirrors.huaweicloud.com/apache/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz解压
[hadoop@cnbugs ~]$ tar xf spark-2.4.4-bin-hadoop2.7.tgz 配置变量
[hadoop@cnbugs ~]$ vim .bashrc
export SPARK_HOME=/home/hadoop/spark-2.4.4-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin[hadoop@cnbugs ~]$ source .bashrc查看spark-shell的路径

配置配置文件
[hadoop@cnbugs ~]$ cd spark-2.4.4-bin-hadoop2.7/conf/
[hadoop@cnbugs conf]$ cp log4j.properties.template log4j.properties修改 log4j.rootCategory 为 WARN, console ,可避免测试中输出太多信息:
把INFO改成WARN,只输出警告信息
[hadoop@cnbugs conf]$ vim log4j.properties
修改spark-env.sh配置变量
[hadoop@cnbugs conf]$ cp spark-env.sh.template spark-env.sh
[hadoop@cnbugs conf]$ vim spark-env.sh
export JAVA_HOME=/usr/java
export SPARK_HOME=/home/hadoop/spark-2.4.4-bin-hadoop2.7
export SCALA_HOME=/home/hadoop/scala-2.11.8spark-env.sh脚本会在启动 Spark 时加载
Spark安装完成!
三、Spark-Shell
Spark-Shell是 Spark 自带的一个 Scala 交互 Shell ,可以以脚本方式进行交互式执行,类似直接用 Python 及其他脚本语言的 Shell 。
进入Spark-Shell只需要执行spark-shell即可:
执行spark-shell
进入到Spark-Shell后可以使用Ctrl D组合键退出 Shell。
在Spark-Shell中我们可以使用 Scala 的语法进行简单的测试,比如我们运行下面几个语句获得文件/etc/protocols的行数以及第一行的内容:
var file = sc.textFile("/etc/protocols")
file.count()
file.first()
上面的操作中创建了一个 RDD file,执行了两个简单的操作:
count()获取 RDD 的行数first()获取第一行的内容
我们继续执行其他操作,比如查找有多少行含有tcp和udp字符串:
file.filter(line => line.contains("tcp")).count()
file.filter(line => line.contains("udp")).count()
查看一共有多少个不同单词的方法,这里用到 Mapreduce 的思路:
var wordcount = file.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
wordcount.count()
上面两步骤我们发现,/etc/protocols中各有一行含有tcp与udp字符串,并且一共有 243 个不同的单词。
上面每个语句的具体含义这里不展开,可以结合你阅读的文章进行理解,后续实验中会不断介绍。这里仅仅提供一个简单的例子让大家对 Spark 运算有基本认识。
操作完成后,Ctrl D组合键退出 Shell。
四、Pyspark
Pyspark 类似 Spark-Shell ,是一个 Python 的交互 Shell 。
执行pyspark启动进入 Pyspark:
pyspark
在 Pyspark 中,我们可以用 Python 语法执行 Spark-Shell 中的操作,比如下面的语句获得文件/etc/protocols 的行数以及第一行的内容:
file = sc.textFile("/etc/protocols")
file.count()
file.first()
五、启动节点
5.1 启动主节点
进入到spark的sbin目录来启动spark主节点服务
[hadoop@cnbugs ~]$ cd spark-2.4.4-bin-hadoop2.7/sbin/
[hadoop@cnbugs sbin]$ ./start-master.sh

查看启动的相关端口

没有报错的话表示 master 已经启动成功,master 默认可以通过 web 访问http://172.18.1.195:8080
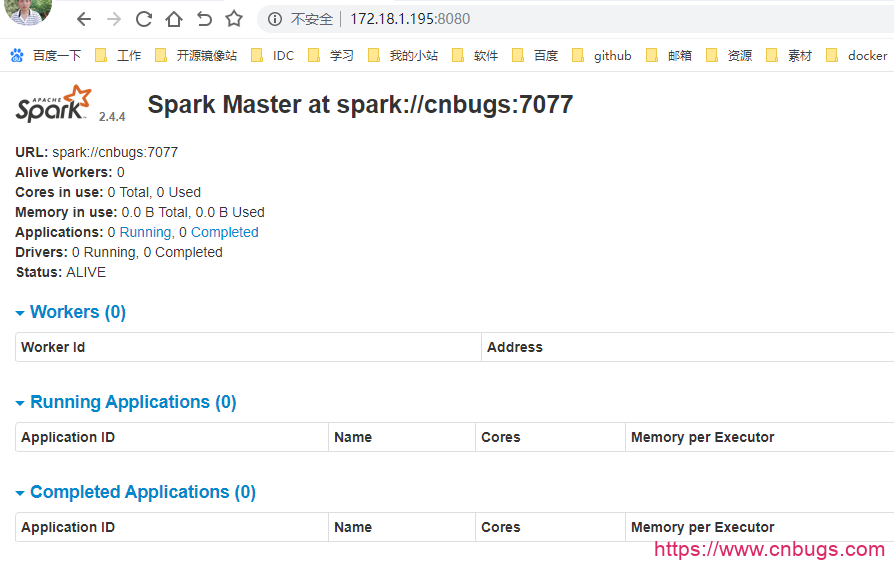
图中所示,master 中暂时还没有一个 worker ,我们启动 worker 时需要 master 的参数,该参数为spark://cnbugs:7077
5.2 启动从节点
[hadoop@cnbugs sbin]$ ./start-slave.sh spark://cnbugs:7077

查看spark的web界面是否有工作节点
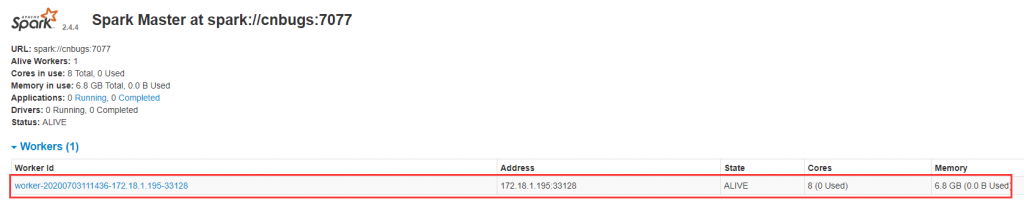
5.3 测试实例
[hadoop@cnbugs sbin]$ MASTER=spark://cnbugs:7077 spark-shell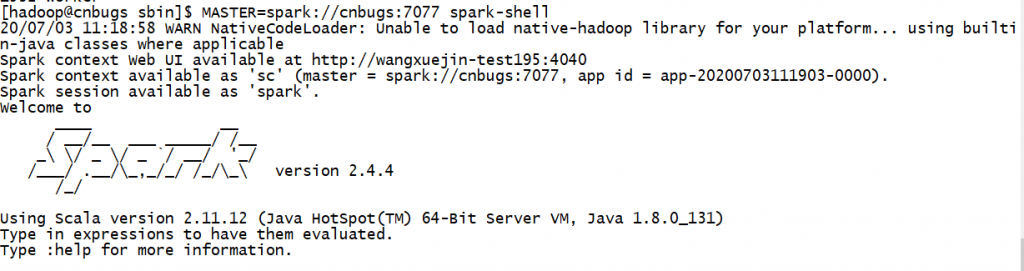
刷新 master 的 web 页面,可以看到新的Running Applications,如下图所示:
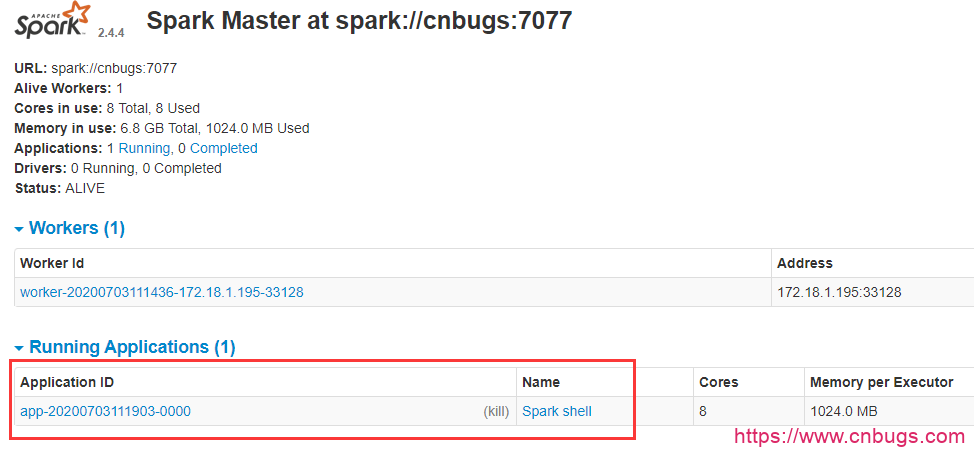
当退出 spark-shell 时,这个 application 会移动到Completed Applications一栏。
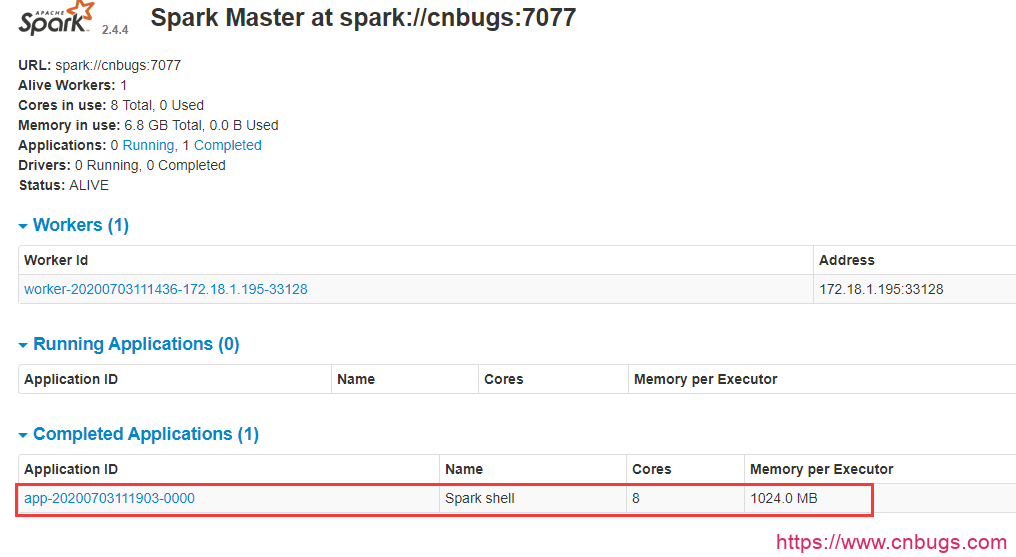
点击页面中的 Application 和 Workers 的链接查看并了解相关信息。
5.4 停止服务
[hadoop@cnbugs sbin]$ ./stop-all.sh
[hadoop@cnbugs sbin]$ jps
六、拓展
Spark集群部署的步骤
上面的步骤介绍了我们在单机模式Standalone Mode下部署的 Spark 环境,如果要部署 Spark 集群稍有区别:
- 主节点上配置 spark ,例如
conf/spark-env.sh中的环境变量 - 主节点上配置
conf/slaves,添加从节点的主机名,注意需要先把所有主机名输入到/etc/hosts避免无法解析 - 把配置好的 spark 目录拷贝到所有从节点,从节点上的目录路径与主节点一致,例如都设置为
/opt/spark-2.3.1-bin-hadoop2.6 - 配置主节点到所有从节点的 SSH 无密码登录,使用
ssh-keygen -t rsa和ssh-copy-id两个命令 - 启动 spark 集群,在主节点上执行
sbin/start-all.sh - 进入主节点的 web 界面查看所有 worker 是否成功启动