Prometheus监控平台基础概念
Prometheus(简称 Prom)是新一代的监控系统,配置简单却灵活,对容器、微服务等支持良好。本次实验我们先来了解一下 Prometheus 的基础概念。
Prometheus 总览
Prometheus 是一个开源监控系统,它前身是 SoundCloud 的告警工具包。从 2012 年开始,许多公司和组织开始使用 Prometheus。该项目的开发人员和用户社区非常活跃,越来越多的开发人员和用户参与到该项目中。目前它是一个独立的开源项目,且不依赖于任何公司。为了强调这点和明确该项目治理结构,Prometheus 在 2016 年继 Kurberntes 之后,加入了 Cloud Native Computing Foundation。
主要特性
- 多维度数据模型
- 灵活的查询语言
- 不依赖任何分布式存储
- 常见方式是通过拉取方式采集数据
- 也可通过中间网关支持推送方式采集数据
- 通过服务发现或者静态配置来发现监控目标
- 支持多种图形界面展示方式
架构
下面这张图描述了 Prometheus 的整体架构,以及其生态中的一些常用组件。
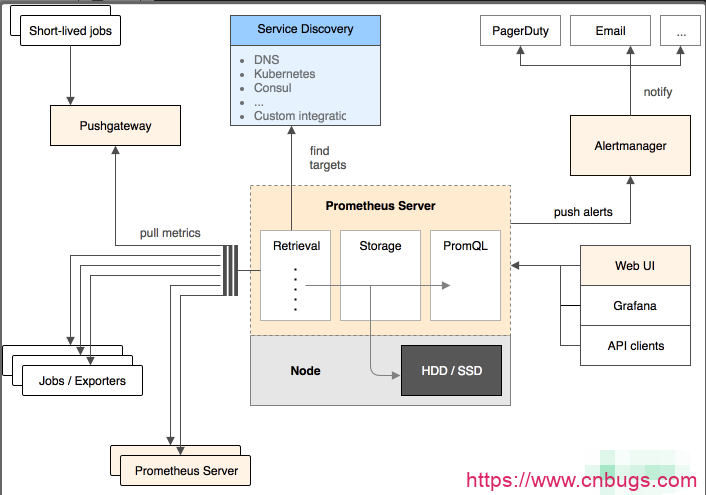
Prometheus Server 采用拉取方式从监控目标直接拉取数据,或者通过中间网关间接地拉取监控目标推送给网关的数据。它在本地存储抓取的数据,通过一定规则进行清理和整理数据,然后把得到的结果存储起来,各种 Web UI 使用 PromQL 查询语言来从 Server 里获取数据。当 Server 监测到有异常时会推送告警给 Alertmanager,Alertmanager 负责去通知相关人。
Prometheus vs Zabbix
- Zabbix 使用的是 C 和 PHP,Prometheus 使用 Golang ,整体而言 Prometheus 运行速度更快一点。
- Zabbix 属于传统主机监控,主要用于物理主机、交换机、网络等监控,Prometheus 不仅适用主机监控,还适用于 Cloud、SaaS、Openstack、Container 监控。
- Zabbix 在传统主机监控方面,有更丰富的插件。
- Zabbix 可以在 WebGui 中配置很多事情,Prometheus 需要手动修改文件配置。
Prometheus vs. Nagios
- Nagios 数据不支持自定义 Labels,不支持查询,告警也不支持去噪、分组,没有数据存储,如果想查询历史状态,需要安装插件。
- Nagios 是上世纪 90 年代的监控系统,比较适合小集群或静态系统的监控。Nagios 太古老,很多特性都没有,Prometheus 要优秀很多。
Prometheus vs Sensu
- Sensu 广义上讲是 Nagios 的升级版本,它解决了很多 Nagios 的问题,如果你对 Nagios 很熟悉,使用 Sensu 是个不错的选择。
- Sensu 依赖 RabbitMQ 和 Redis,数据存储上扩展性更好。
Prometheus vs InfluxDB
- InfluxDB 是一个开源的时序数据库,主要用于存储数据,如果想搭建监控告警系统,需要依赖其他系统。
- InfluxDB 在存储水平扩展以及高可用方面做的更好,毕竟核心是数据库。
数据模型
Prometheus 从根本上存储的所有数据都是时间序列数据(Time Serie Data,简称时序数据)。时序数据是具有时间戳的数据流,该数据流属于某个度量指标(Metric)和该度量指标下的多个标签(Label)。除了提供存储功能,Prometheus 还可以利用查询表达式来执行非常灵活和复杂的查询。
度量指标和标签
每个时间序列(Time Serie,简称时序)由度量指标和一组标签键值对唯一确定。
度量指标名称描述了被监控系统的某个测量特征(比如 http_requests_total 表示 http 请求总数)。度量指标名称由 ASCII 字母、数字、下划线和冒号组成,须匹配正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]*。
标签开启了 Prometheus 的多维数据模型。对于同一个度量指标,不同标签值组合会形成特定维度的时序。Prometheus 的查询语言可以通过度量指标和标签对时序数据进行过滤和聚合。改变任何度量指标上的任何标签值,都会形成新的时序。标签名称可以包含 ASCII 字母、数字和下划线,须匹配正则表达式 [a-zA-Z_][a-zA-Z0-9_]*,带有 _ 下划线的标签名称保留为内部使用。标签值可以包含任意 Unicode 字符,包括中文。
采样值(Sample)
时序数据其实就是一系列采样值。每个采样值包括:
- 一个 64 位的浮点数值
- 一个精确到毫秒的时间戳
注解(Notation)
一个注解由一个度量指标和一组标签键值对构成。形式如下:
[metric name]{[label name]=[label value], ...}例如,度量指标为 api_http_requests_total,标签为 method="POST"、handler="/messages" 的注解表示如下:
api_http_requests_total{method="POST", handler="/messages"}Prometheus 里的度量指标有以下几种类型:
计数器(Counter)
计数器是一种累计型的度量指标,它是一个只能递增的数值。计数器主要用于统计类似于服务请求数、任务完成数和错误出现次数这样的数据。
计量器(Gauge)
计量器表示一个既可以增加,又可以减少的度量指标值。计量器主要用于测量类似于温度、内存使用量这样的瞬时数据。
直方图(Histogram)
直方图对观察结果(通常是请求持续时间或者响应大小这样的数据)进行采样,并在可配置的桶中对其进行统计。有以下几种方式来产生直方图(假设度量指标为 <basename>):
- 按桶计数,相当于
<basename>_bucket{le="<upper inclusive bound>"} - 采样值总和,相当于
<basename>_sum - 采样值总数,相当于
<basename>_count,也等同于把所有采样值放到一个桶里来计数<basename>_bucket{le="+Inf"}
汇总(Summary)
类似于直方图,汇总也对观察结果进行采样。除了可以统计采样值总和和总数,它还能够按分位数统计。有以下几种方式来产生汇总(假设度量指标为 <basename>):
- 按分位数,也就是采样值小于该分位数的个数占总数的比例小于φ,相当于
<basename>{quantile="<φ>"} - 采样值总和,相当于
<basename>_sum - 采样值总数,相当于
<basename>_count
在 Prometheus 里,可以从中抓取采样值的端点称为实例,为了性能扩展而复制出来的多个这样的实例形成了一个任务。
例如下面的 api-server 任务有四个相同的实例:
job: api-server
instance 1: 1.2.3.4:5670
instance 2: 1.2.3.4:5671
instance 3: 5.6.7.8:5670
instance 4: 5.6.7.8:5671Prometheus 抓取完采样值后,会自动给采样值添加下面的标签和值:
- job: 抓取所属任务。
- instance: 抓取来源实例
另外每次抓取时,Prometheus 还会自动在以下时序里插入采样值:
up{job="[job-name]", instance="instance-id"}: 采样值为 1 表示实例健康,否则为不健康scrape_duration_seconds{job="[job-name]", instance="[instance-id]"}: 采样值为本次抓取消耗时间scrape_samples_post_metric_relabeling{job="<job-name>", instance="<instance-id>"}: 采样值为重新打标签后的采样值个数scrape_samples_scraped{job="<job-name>", instance="<instance-id>"}: 采样值为本次抓取到的采样值个数