Filebeat + ELK 实现海量日志采集最佳实践
Filebeat + ELK 实现海量日志采集最佳实践
在 ELK 生态系统中,Logstash 作为日志采集和处理的中心节点功能强大,但它在高并发场景下存在资源消耗高、采集效率瓶颈等问题。Filebeat 作为 Elastic 官方推出的轻量级日志采集器,完美地填补了这一空白。本文将深入讲解 Filebeat 的架构原理、核心配置以及在生产环境中的最佳实践。
一、为什么需要 Filebeat
1.1 Logstash 的局限性
Logstash 基于 JRuby 实现,运行在 JVM 之上,默认配置下内存占用通常在 1GB 以上。在需要大规模日志采集的场景中,如果每个业务服务器都部署 Logstash,将带来巨大的资源开销。此外,Logstash 的采集性能受到 JVM GC 和插件 pipeline 的影响,在高吞吐场景下容易出现背压问题。
1.2 Filebeat 的优势
- 轻量级:基于 Go 语言编写,二进制文件仅 10MB+,内存占用通常 20-50MB
- 零依赖:无需 JVM、无需其他运行时环境,解压即用
- 背压感知:内置背压协议,当下游(Logstash/Elasticsearch)繁忙时自动减速
- 断点续传:通过 registry 文件记录采集偏移量,重启后自动从断点继续采集
- 天生免运维:无需复杂的 pipeline 配置,开箱即用
1.3 分层采集架构
推荐的生产架构是 Filebeat → Logstash → Elasticsearch,而不是 Filebeat → Elasticsearch。Filebeat 负责"采集"和"传输",Logstash 负责"解析"和"富化",各司其职,实现采集与处理相分离。
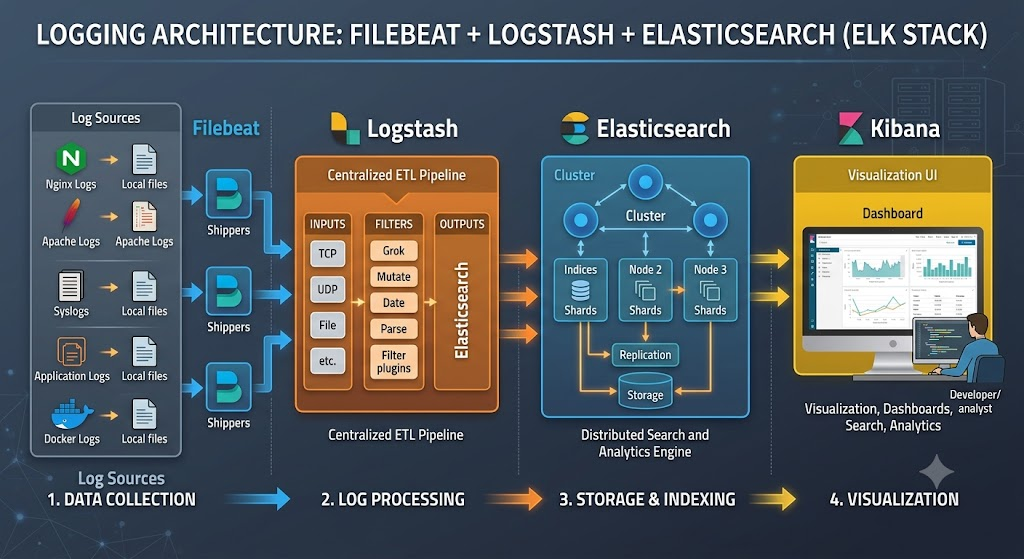
二、Filebeat 架构详解
2.1 核心组件
- Harvester(收割者):每个日志文件对应一个 harvester 实例,负责逐行读取文件内容并发送到 spooler。如果文件被轮转或删除,对应的 harvester 会自动关闭并释放资源。
- Prospector(探勘者):负责管理 harvester 的生命周期,根据配置的文件路径(glob pattern)发现新的日志文件,并为其创建 harvester。prospector 还会检测之前跟踪的文件是否被删除或轮转。
- Input(输入):Filebeat 7.x+ 引入了 Input 概念替代了旧的 Prospector 模型,每个输入类型(log、stdin、container、syslog 等)都有独立的配置块。
2.2 Registry 文件
Registry 是 Filebeat 的"记忆文件",默认位于 data/registry/filebeat/log.json。它记录了每个被采集文件的偏移量(offset)、文件状态、元数据等信息。当 Filebeat 重启时,会从 registry 中读取状态,确保只采集新增的日志数据。
Registry 的核心字段:
| 字段 | 说明 |
|---|---|
source | 文件完整路径 |
offset | 已读取的字节偏移量 |
timestamp | 最后更新时间 |
ttl | 文件超时时间,超过后从 registry 移除 |
type | 输入类型(log/container 等) |
FileStateOS | 文件 inode 和设备号,用于识别被轮转的文件 |
2.3 数据处理流水线
Filebeat 内部的数据流如下:
Harvester → Spooler → Publisher → Output
- Spooler:将多条事件合并成批量(batch),提高网络传输效率
- Publisher:管理输出队列,实现背压控制和 ACK 确认
- Output:支持 Elasticsearch、Logstash、Kafka、Redis 等多种输出方式
三、Filebeat 安装和基础配置
3.1 安装方式
方式一:apt/yum 安装(推荐)
<pre class="wp-block-code"><code># Debian/Ubuntu
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo gpg --dearmor -o /usr/share/keyrings/elasticsearch-keyring.gpg
echo "deb [signed-by=/usr/share/keyrings/elasticsearch-keyring.gpg] https://artifacts.elastic.co/packages/8.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-8.x.list
sudo apt-get update && sudo apt-get install filebeat
# CentOS/RHEL
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
cat <<EOF | sudo tee /etc/yum.repos.d/elastic.repo
[elastic-8.x]
name=Elastic repository for 8.x packages
baseurl=https://artifacts.elastic.co/packages/8.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF
sudo yum install filebeat</code></pre>
方式二:二进制安装
从 Elastic 官网下载对应平台的 tar.gz 压缩包,解压后直接运行 ./filebeat -c filebeat.yml 即可。
3.2 基础配置示例
以下是一个采集 Nginx 访问日志并发送到 Logstash 的完整配置:
<pre class="wp-block-code"><code># filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
- /var/log/nginx/error.log
fields:
service: nginx
env: production
fields_under_root: true # 将字段放在根层级
- type: log
enabled: true
paths:
- /var/log/mysql/mysql-slow.log
fields:
service: mysql
multiline:
type: pattern
pattern: '^# Time:'
negate: true
match: after
# 输出到 Logstash
output.logstash:
hosts: ["192.168.1.100:5044"]
# 日志记录
logging.level: info
logging.to_files: true
logging.files:
path: /var/log/filebeat
name: filebeat.log
keepfiles: 7
permissions: 0644</code></pre>
四、Filebeat + Logstash + Elasticsearch 完整链路
4.1 Logstash 端配置
Logstash 使用 beats 输入插件接收 Filebeat 发送的数据:
<pre class="wp-block-code"><code># logstash.conf
input {
beats {
port => 5044
host => "0.0.0.0"
ssl => true
ssl_certificate => "/etc/logstash/ssl/logstash.crt"
ssl_key => "/etc/logstash/ssl/logstash.key"
}
}
filter {
if [service] == "nginx" {
grok {
match => {
"message" => '%{IPORHOST:client_ip} - - \[%{HTTPDATE:timestamp}\] "%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:http_version}" %{NUMBER:response_code} %{NUMBER:body_sent_bytes} "%{DATA:referrer}" "%{DATA:user_agent}"'
}
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
useragent {
source => "user_agent"
target => "user_agent_parsed"
}
geoip {
source => "client_ip"
target => "geoip"
}
}
if [service] == "mysql" {
grok {
match => {
"message" => "# Time: %{DATA:query_time}\n# User@Host: %{DATA:user_host}\n# Query_time: %{NUMBER:query_secs:float} Lock_time: %{NUMBER:lock_secs:float} Rows_sent: %{NUMBER:rows_sent:int} Rows_examined: %{NUMBER:rows_examined:int}\nSET timestamp=%{NUMBER:mysql_timestamp};\n%{GREEDYDATA:sql_query}"
}
}
}
mutate {
remove_field => ["message", "original", "tags"]
}
}
output {
elasticsearch {
hosts => ["https://elasticsearch1:9200", "https://elasticsearch2:9200"]
index => "filebeat-%{[service]}-%{+YYYY.MM.dd}"
user => "logstash_writer"
password => "${ES_PASSWORD}"
ssl => true
cacert => "/etc/logstash/ssl/ca.crt"
}
}</code></pre>
4.2 数据流全景
| 环节 | 组件 | 职责 |
|---|---|---|
| 1 | Filebeat | 从日志文件中读取新行,加入元数据(service、env),发送到 Logstash |
| 2 | Logstash | Grok 解析、GeoIP 地理定位、UserAgent 解析、时间戳标准化 |
| 3 | Elasticsearch | 分布式存储和全文搜索,按 service + 日期创建索引 |
| 4 | Kibana | 可视化展示(Data View、Dashboards、Alerting) |
五、Filebeat Module 使用
Filebeat Module 是预配置的采集模块,涵盖常见应用和系统日志。启用一个 Module 即可自动完成路径检测、字段映射、索引模板、Kibana 仪表板的配置。
5.1 常用 Module
| Module | 采集内容 | 配置示例 |
|---|---|---|
| system | 系统日志、认证日志、sudo 日志 | filebeat modules enable system |
| nginx | 访问日志、错误日志 | filebeat modules enable nginx |
| mysql | 慢查询日志、错误日志 | filebeat modules enable mysql |
| redis | 慢日志、运行时日志 | filebeat modules enable redis |
| elasticsearch | ES 审计、慢查询、GC 日志 | filebeat modules enable elasticsearch |
| docker | 容器标准输出/标准错误 | filebeat modules enable docker |
| kafka | Kafka 服务器日志 | filebeat modules enable kafka |
5.2 配置 System Module
<pre class="wp-block-code"><code># 1. 启用 system module
filebeat modules enable system
# 2. 修改模块配置 /etc/filebeat/modules.d/system.yml
- module: system
syslog:
enabled: true
var.paths: ["/var/log/syslog"]
auth:
enabled: true
var.paths: ["/var/log/auth.log"]
sudo:
enabled: true
var.paths: ["/var/log/sudo.log"]
# 3. 配置输出
output.elasticsearch:
hosts: ["localhost:9200"]
username: "elastic"
password: "changeme"
# 4. 加载 Kibana 仪表板
filebeat setup -e \
-E setup.dashboards.enabled=true \
-E setup.kibana.host=http://localhost:5601
# 5. 启动
systemctl start filebeat</code></pre>
5.3 Module 的核心价值
- 免 Grok 解析:Module 内置了完整的 Grok 模式和字段映射
- 免索引模板:自动创建 Elasticsearch 索引模板/组件模板
- 免仪表板配置:直接安装预制的 Kibana 仪表板,开箱即用
- 保持兼容性:Module 会随着 Elastic Stack 版本更新而同步更新
六、多行日志合并配置(Multiline)
Java 堆栈跟踪、MySQL 慢查询、SQL 日志等往往跨越多行,需要将多行合并为单一事件。Filebeat 的 multiline 配置在 input 级别处理。
6.1 Multiline 模式
| 参数 | 说明 | 常用值 |
|---|---|---|
type | 匹配类型 | pattern(正则模式)、count(固定行数) |
pattern | 正则表达式 | 如 '^\[ERROR\]' 表示以 [ERROR] 开头的行为新事件开始 |
negate | 是否取反匹配 | true 或 false |
match | 合并方向 | after(将匹配的行附加到前一行之后)或 before |
timeout | 最大等待时间 | 如 5s,超时后强制刷新缓存的事件 |
max_lines | 单个事件最大行数 | 如 500,防止内存无限增长 |
max_bytes | 单个事件最大字节 | 如 10MB |
6.2 Java 异常栈合并
<pre class="wp-block-code"><code>filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/app/java.log
multiline:
type: pattern
pattern: '^\d{4}-\d{2}-\d{2}' # 以日期开头是新事件
negate: true
match: after</code></pre>
6.3 MySQL 慢查询合并
<pre class="wp-block-code"><code>filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/mysql/mysql-slow.log
multiline:
type: pattern
pattern: '^# Time:|^# User@Host:'
negate: true
match: after
timeout: 10s
max_lines: 500</code></pre>
6.4 固定行数合并
对于格式完全固定的日志,可以使用 count 模式:
<pre class="wp-block-code"><code>multiline:
type: count
count_lines: 5 # 每 5 行合并为一个事件</code></pre>
七、性能优化
7.1 核心优化参数
| 参数 | 默认值 | 优化建议 | 说明 |
|---|---|---|---|
harvester_buffer_size | 16384 (16KB) | 65536 (64KB) | 每次读取文件的缓冲区大小,增大可减少系统调用次数 |
max_bytes | 10MB | - | 单行日志最大长度,超过则截断 |
backoff.init | 1s | 5s | 文件末尾无新数据时的初始等待时间 |
backoff.max | 60s | 60s | 最大等待时间,避免空转时频繁轮询 |
max_backoff | 60s | 300s | 当文件长时间无变化时的退避上限 |
close_inactive | 5m | 30m | 文件无更新超过此时长后关闭 harvester |
close_removed | true | true | 文件被删除/轮转后关闭 harvester |
clean_inactive | 0(禁用) | 72h | 从 registry 中清理长时间无更新的文件记录 |
queue.mem.events | 4096 | 8192 | 内存队列缓冲事件数 |
queue.mem.flush.min_events | 2048 | 4096 | 触发 flush 的最小事件数 |
queue.mem.flush.timeout | 1s | 2s | 触发 flush 的超时时间 |
7.2 性能优化完整配置
<pre class="wp-block-code"><code>filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/**/*.log
harvester_buffer_size: 65536 # 64KB 缓冲区
max_bytes: 10485760 # 10MB 单行限制
# 退避策略
backoff:
init: 5s # 初始等待 5s
max: 60s # 最大等待 60s
max_backoff: 300s # 文件长期无变化时退避到 5 分钟
# 资源管理
close_inactive: 30m # 30 分钟无更新关闭 harvester
close_removed: true
close_renamed: true
clean_inactive: 72h # 72 小时清理 registry 记录
scan_frequency: 30s # 扫描新文件的频率
# 内存队列
queue.mem:
events: 8192 # 最多缓存 8192 个事件
flush.min_events: 4096 # 4096 个事件触发 flush
flush.timeout: 2s # 最多等待 2s
# 输出配置
output.logstash:
hosts: ["logstash1:5044", "logstash2:5044"]
loadbalance: true # 启用负载均衡
worker: 4 # 输出 worker 数量
bulk_max_size: 2048 # 批量发送大小</code></pre>
7.3 操作系统级优化
- 调整 inotify 限制:
fs.inotify.max_user_watches = 524288(避免文件监听不足) - 使用 tcp_bbr 拥塞控制:优化 Filebeat → Logstash 的 TCP 传输性能
- 关闭 swap:Filebeat 应该常驻内存,避免被换出影响采集实时性
八、数据安全和 SSL/TLS 配置
生产环境中,Filebeat 与 Logstash/Elasticsearch 之间的通信必须加密,防止日志数据在传输过程中被窃听或篡改。
8.1 生成 SSL 证书
<pre class="wp-block-code"><code># 1. 生成 CA 证书
openssl req -new -x509 -days 3650 -nodes \
-out ca.crt -keyout ca.key \
-subj "/CN=Elastic CA"
# 2. 为 Logstash 生成证书
openssl req -new -nodes \
-out logstash.csr -keyout logstash.key \
-subj "/CN=logstash.example.com"
openssl x509 -req -days 3650 \
-in logstash.csr -CA ca.crt -CAkey ca.key -CAcreateserial \
-out logstash.crt
# 3. 为 Filebeat 生成客户端证书(可选双向认证)
openssl req -new -nodes \
-out filebeat.csr -keyout filebeat.key \
-subj "/CN=filebeat-client"
openssl x509 -req -days 3650 \
-in filebeat.csr -CA ca.crt -CAkey ca.key -CAcreateserial \
-out filebeat.crt</code></pre>
8.2 Filebeat 端 SSL 配置
<pre class="wp-block-code"><code># filebeat.yml
output.logstash:
hosts: ["logstash1:5044", "logstash2:5044"]
loadbalance: true
ssl:
certificate_authorities: ["/etc/filebeat/ssl/ca.crt"]
certificate: "/etc/filebeat/ssl/filebeat.crt" # 客户端证书(双向认证)
key: "/etc/filebeat/ssl/filebeat.key" # 客户端密钥
verification_mode: full # 验证服务器证书
supported_protocols: [TLSv1.2, TLSv1.3] # 安全协议版本
# 也可以输出到 Elasticsearch 并启用 SSL
output.elasticsearch:
hosts: ["https://elasticsearch1:9200", "https://elasticsearch2:9200"]
protocol: "https"
ssl.verification_mode: full
ssl.certificate_authorities: ["/etc/filebeat/ssl/ca.crt"]
username: "filebeat_writer"
password: "${ES_PASSWORD}"</code></pre>
8.3 Logstash 端 SSL 配置
<pre class="wp-block-code"><code># logstash.conf
input {
beats {
port => 5044
host => "0.0.0.0"
ssl => true
ssl_certificate_authorities => ["/etc/logstash/ssl/ca.crt"]
ssl_certificate => "/etc/logstash/ssl/logstash.crt"
ssl_key => "/etc/logstash/ssl/logstash.key"
ssl_verify_mode => "peer" # 验证客户端证书(双向认证)
ssl_client_authentication => "required"
}
}</code></pre>
8.4 Elasticsearch 安全建议
- 启用 Elasticsearch 内置安全功能(xpack.security.enabled=true)
- 为 Filebeat 创建专用角色和用户,权限最小化
- 开启审计日志(audit.enabled=true)
- 使用 Elastic Agent + Fleet 集中管理 Filebeat 配置
九、生产环境注意事项
- Registry 文件备份:定期备份
data/registry/目录,防止 registry 损坏导致重复采集 - 日志轮转兼容:Filebeat 依赖文件的 inode 检测轮转,确保日志轮转后旧文件不会立即被删除(建议保留至少 2 个轮转文件)
- 调试模式:使用
filebeat -e -d "*"打印详细调试日志,排查采集问题 - 版本匹配:Filebeat 版本应与 Elasticsearch 大版本保持一致(建议 8.x 全系列匹配)
- 监控 Filebeat 自身状态:通过
http.enabled: true暴露监控 API,Prometheus 采集 - 避免采集自身日志:配置中不要包含 Filebeat 自身的日志路径,防止死循环
总结
Filebeat 作为 ELK 生态的"特洛伊木马",以其轻量、稳定、高性能的特性成为大规模日志采集的标准选择。配合 Logstash 的解析能力和 Elasticsearch 的搜索分析能力,可以构建一套完整、可靠、安全的日志采集处理流水线。在实际部署中,应根据业务场景合理配置 multiline 规则、调优 backoff 策略,并始终启用 SSL/TLS 加密传输,确保生产环境的稳定与安全。
下一步,我们将深入探讨 Elasticsearch 索引模板、ILM 索引生命周期管理和冷热架构,敬请关注本系列后续文章。
ELK 系列文章总目录
- 第1篇:ELK Stack 入门:Elasticsearch + Logstash + Kibana 架构解析
- 第2篇:Elasticsearch 集群部署与核心概念
- 第3篇:Logstash 数据采集与 Pipeline 实战
- 第4篇:Kibana 数据可视化与仪表板
- 第5篇:Elasticsearch 查询 DSL 从入门到精通
- 第6篇:Elasticsearch 索引管理与性能调优
- 第7篇:Filebeat + ELK 实现海量日志采集最佳实践







