Logstash 管道配置实战:从入门到精通
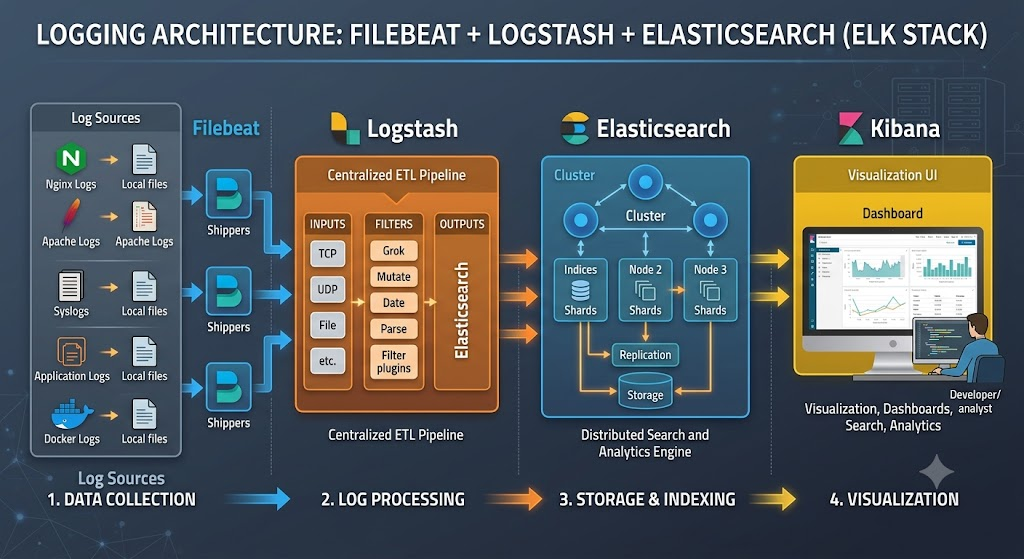
一、Logstash 管道架构:三段式数据流
Logstash的管道(Pipeline)由三个阶段构成,数据依次流经这三个阶段:
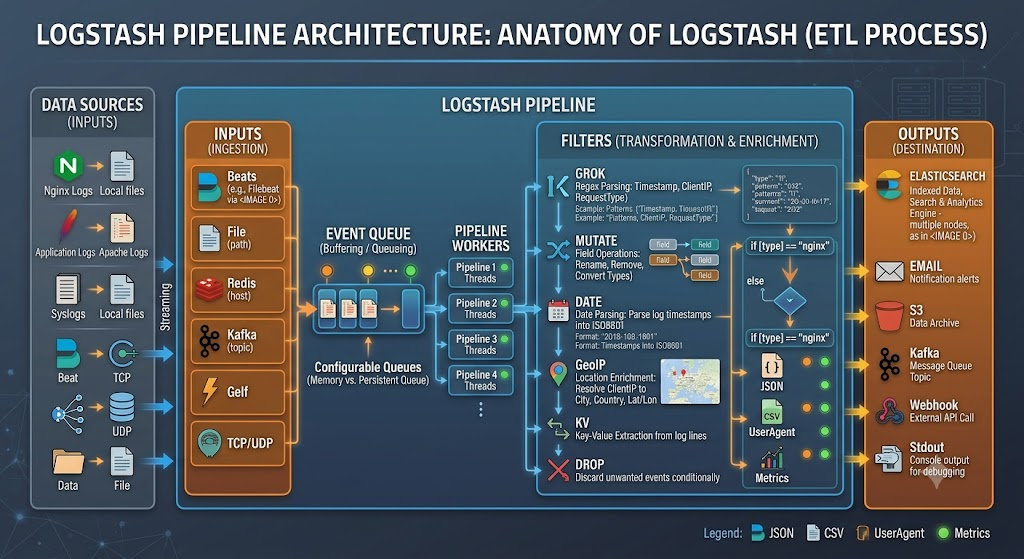
- Input(输入):定义数据来源。Logstash支持从文件、网络端口、消息队列、数据库等多种源拉取或接收数据。
每个input插件在一个独立的线程中运行,将事件推入中央队列。 - Filter(过滤):对数据执行解析、转换、增强和格式化。这是Logstash最强大的环节,能够将非结构化日志转化为结构化JSON。
Filter阶段是一个顺序执行的处理器链,按照配置顺序依次执行各个filter插件。 - Output(输出):将处理后的数据发送到目标系统。最常用的目标为Elasticsearch,此外也支持文件存储、消息队列、监控系统等。
多个output可以并行输出到不同目标。
核心配置示例(单管道):
input {
beats {
port => 5044
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "apache-logs-%{+YYYY.MM.dd}"
}
}二、常用 Input 插件详解
2.1 file 插件
file插件用于从本地日志文件中逐行读取新内容,行为类似于tail -f。它使用sincedb文件记录读取位置,确保Logstash重启后不会重复或丢失数据。
input {
file {
path => "/var/log/nginx/access.log"
start_position => "beginning"
sincedb_path => "/var/lib/logstash/sincedb_nginx"
type => "nginx-access"
}
}| 参数 | 说明 | 默认值 |
|---|---|---|
path |
要监视的日志文件路径(支持通配符如/var/log/*.log) |
必填 |
start_position |
初始读取位置:beginning或end |
end |
sincedb_path |
sincedb文件路径,设为/dev/null则每次从头读取 |
自动 |
stat_interval |
检查文件变化的时间间隔(秒) | 1 |
2.2 beats 插件
接收来自Filebeat、Metricbeat、Winlogbeat等Beats家族的数据。这是生产环境中最推荐的Logstash输入方式,因为Beats作为轻量级采集器部署在客户端,通过SSL加密传输到中央Logstash。
input {
beats {
port => 5044
ssl => true
ssl_certificate => "/etc/logstash/ssl/logstash.crt"
ssl_key => "/etc/logstash/ssl/logstash.key"
}
}2.3 tcp 插件
通过TCP协议接收日志数据,适合自定义客户端或非Beats场景。支持JSON解码、SSL等高级功能。
input {
tcp {
port => 4560
mode => "server"
codec => json
}
}2.4 syslog 插件
直接监听UDP或TCP端口接收RFC 3164 / RFC 5424格式的syslog消息,自动解析标准syslog头部字段。
input {
syslog {
port => 514
type => "syslog"
}
}2.5 http 插件
启动一个HTTP/HTTPS服务器端点,接收外部系统通过POST/PUT等方式发送的JSON数据。适合Webhook集成场景。
input {
http {
port => 8080
codec => json
}
}三、常用 Filter 插件实战
3.1 grok — 日志解析的核心武器
grok是Logstash最强大、最复杂的filter插件。它通过正则表达式模式匹配,将非结构化的文本行转换为结构化字段。Grok建立在正则表达式之上,但提供了数百个预定义的模式(pattern),使常见的日志格式解析变得轻而易举。
基本语法:%{PATTERN_NAME:field_name}
filter {
grok {
match => { "message" => "%{IP:client_ip} - - \[%{HTTPDATE:timestamp}\] \"%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:http_version}\" %{NUMBER:status} %{NUMBER:bytes}" }
}
}解析结果:
{
"client_ip": "192.168.1.1",
"timestamp": "10/Jun/2025:08:15:30 +0000",
"method": "GET",
"request": "/api/users",
"http_version": "1.1",
"status": "200",
"bytes": "1234"
}常用Grok模式速查表:
| 模式名 | 匹配内容 | 示例 |
|---|---|---|
%{IP} |
IPv4 / IPv6地址 | 192.168.1.1 |
%{IPORHOST} |
IP或主机名 | server-01 |
%{HTTPDATE} |
Apache/nginx日志时间 | 10/Jun/2025:08:15:30 +0000 |
%{URIPATHPARAM} |
URI路径+参数 | /api/users?id=123 |
%{COMBINEDAPACHELOG} |
Apache组合日志完整模式 | — |
%{NUMBER} |
整数或浮点数 | 200, 3.14 |
%{GREEDYDATA} |
匹配任意字符(贪婪) | anything here |
%{UUID} |
UUID格式 | 550e8400-e29b-41d4-a716-446655440000 |
3.2 mutate — 字段转换与处理
用于对字段进行增删改查操作,是数据清洗的"瑞士军刀"。
filter {
mutate {
remove_field => ["@version", "host", "path"]
rename => { "message" => "raw_log" }
convert => { "response_time" => "float" }
gsub => ["message", "\t", " "]
uppercase => ["log_level"]
lowercase => ["service_name"]
}
}| 指令 | 用途 |
|---|---|
remove_field |
删除指定字段 |
rename |
重命名字段 |
convert |
字段类型转换 |
gsub |
全局替换(正则) |
uppercase/lowercase |
转大写/小写 |
split |
按分隔符拆分字段为数组 |
join |
将数组合并为字符串 |
3.3 date — 时间戳解析与标准化
将日志中的时间字符串解析为Logstash的@timestamp字段,确保Elasticsearch按正确时间排序。
filter {
date {
match => ["log_time", "ISO8601", "yyyy/MM/dd HH:mm:ss"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
}
# 常见日期格式
# "dd/MMM/yyyy:HH:mm:ss Z" → 10/Jun/2025:08:15:30 +0000
# "yyyy-MM-dd HH:mm:ss" → 2025-06-10 08:15:30
# "ISO8601" → 2025-06-10T08:15:30.000Z3.4 geoip — IP地理定位增强
根据IP地址自动添加地理位置信息,包括经纬度、国家、城市、ASN等,非常适合做地理分布可视化。
filter {
geoip {
source => "client_ip"
target => "geo"
database => "/etc/logstash/GeoLite2-City.mmdb"
fields => ["city_name", "country_name", "location", "region_name"]
}
}3.5 useragent — 用户代理解析
将HTTP User-Agent字符串拆解为浏览器名称、版本、操作系统、设备类型等结构化字段。
filter {
useragent {
source => "user_agent"
target => "ua"
}
}
# 解析后得到的字段:
# ua.name → "Chrome"
# ua.major → "120"
# ua.minor → "0"
# ua.os_name → "Windows"
# ua.os_version → "10"
# ua.device → "Other"四、Output 插件配置
4.1 elasticsearch — 核心输出
output {
elasticsearch {
hosts => ["https://es-node1:9200", "https://es-node2:9200"]
index => "%{[@metadata][index_prefix]}-%{+YYYY.MM.dd}"
user => "logstash_writer"
password => "${ES_PWD}"
ssl => true
cacert => "/etc/logstash/ssl/ca.crt"
manage_template => false
ilm_enabled => true
ilm_rollover_alias => "weblogs"
ilm_pattern => "{now/d}-000001"
}
}4.2 file — 文件输出
将处理后的数据写入本地文件,常用于调试或历史归档:
output {
file {
path => "/data/logstash/output/%{+YYYY/MM/dd}/app-%{server_name}.log"
codec => json_lines
}
}4.3 stdout — 调试输出
输出到控制台,是开发和调试阶段最常用的输出:
output {
stdout {
codec => rubydebug
}
}
# rubydebug 输出带颜色的结构化格式,便于人类阅读
# 其他可选 codec:json, json_lines, line五、Grok 正则表达式详解与调试
5.1 自定义Grok模式
当内置模式不够用时,可以定义自己的模式。两种方式:
方式一:内联定义(patterns_dir)
filter {
grok {
patterns_dir => ["/etc/logstash/patterns"]
match => { "message" => "%{MYAPPLOG}" }
}
}
# /etc/logstash/patterns/custom 文件内容:
# MYAPPLOG %{TIMESTAMP_ISO8601:log_time} \[%{LOGLEVEL:level}\] %{DATA:class} - %{GREEDYDATA:msg}方式二:行内定义(正则直接嵌入)
filter {
grok {
match => { "message" => "(?\d{3}-\d{2}-\d{4})" }
}
} 5.2 Grok调试方法
在线调试工具:
- Grok Debugger(Elasticsearch Kibana自带):Management → Dev Tools → Grok Debugger。直接在Kibana中测试模式。
- Grok Constructor(https://grokconstructor.appspot.com):在线正则生成与测试工具。
- Logstash本地调试:使用
stdout { codec => rubydebug }输出方便调试的结构化数据。
命令行调试:
# 使用 logstash 的 -e 参数直接传入配置运行
bin/logstash -e 'input { stdin {} } filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}" } } } output { stdout { codec => rubydebug } }'
# 然后粘贴日志样本,即可看到解析结果5.3 Grok匹配失败的常见原因
- 模式顺序错误:多个
match按顺序尝试,break_on_match控制是否命中即停止 - 特殊字符未转义:
[]、()、|、\在日志中需要转义 - 字段存在或不存在空的处理:使用
%{DATA:field_name}代替%{GREEDYDATA:field_name}来避免过度匹配 - 日志格式有变:应用升级或配置变更导致日志格式变化
失败处理配置:
filter {
grok {
match => { "message" => ["%{COMBINEDAPACHELOG}", "%{COMMONAPACHELOG}"] }
tag_on_failure => ["_grok_failure", "parse_failed"]
add_tag => ["parsed_success"]
}
}六、多管道配置(pipelines.yml)
生产环境中,通常需要同时处理多种不同类型的数据源。Logstash支持在同一进程中运行多个独立的管道,通过pipelines.yml文件进行配置。
6.1 基本配置示例
# /etc/logstash/pipelines.yml
# 管道1: 处理 Nginx 访问日志
- pipeline.id: nginx-access
path.config: "/etc/logstash/conf.d/nginx-access.conf"
pipeline.workers: 2
# 管道2: 处理系统 syslog
- pipeline.id: syslog
path.config: "/etc/logstash/conf.d/syslog.conf"
pipeline.workers: 4
pipeline.batch.size: 250
# 管道3: 处理应用日志(JSON格式)
- pipeline.id: app-logs
path.config: "/etc/logstash/conf.d/app-logs.conf"
pipeline.workers: 2
pipeline.batch.delay: 506.2 多管道的优势
- 资源隔离:每个管道独立配置
workers、batch.size等参数,高吞吐管道不会拖慢低优先级管道 - 故障隔离:单个管道的故障不会影响其他管道
- 配置分离:不同数据源对应不同配置文件,便于管理和团队协作
- 弹性管理:支持
pipeline.ordered控制事件顺序,支持queue.type配置持久化队列
6.3 管道间数据传递
Logstash 6.x+ 支持跨管道数据传递:
# 管道A(生成事件)
output {
pipeline { send => ["shared-channel"] }
}
# 管道B(接收事件)
input {
pipeline { address => "shared-channel" }
}七、性能调优指南
从单机采集到企业级日均TB级数据处理,Logstash的性能调优是运维中的关键环节。
7.1 核心调优参数
| 参数 | 默认值 | 说明 | 建议 |
|---|---|---|---|
pipeline.workers |
CPU核心数 | Filter/Output阶段的并行线程数 | 设为CPU核心数×1.5~2 |
pipeline.batch.size |
125 | 单批次处理的事件数 | 500~2000(取决于事件大小) |
pipeline.batch.delay |
50 (ms) | 批量派发的等待时间 | 50~100(吞吐优先可降低) |
queue.type |
memory | 事件队列类型(memory或persisted) | 生产环境使用persisted |
queue.max_bytes |
1GB | 持久化队列总大小 | 视可用内存和硬盘调整 |
7.2 JVM堆内存配置
# /etc/logstash/jvm.options
-Xms4g
-Xmx4g
# 建议:堆内存设为物理内存的50%~60%,但不要超过8GB
# 过大堆内存会导致 GC 暂停时间增加7.3 持久化队列配置
使用持久化队列可以在Logstash重启时保证不丢数据:
# /etc/logstash/logstash.yml
queue.type: persisted
queue.max_bytes: 8gb
queue.checkpoint.writes: 1000
# 每个管道可独立覆盖
# pipeline.workers: 4
# pipeline.batch.size: 5007.4 其他关键调优策略
- 减少grok复杂度:优先使用简化模式,避免大量
GREEDYDATA嵌套;多个grok匹配时使用break_on_match - 减少不必要的filter:不需要的字段尽早用
mutate { remove_field }移除 - 使用条件判断:不同类型的事件使用不同的filter链,减少CPU浪费
- 编码优化:优先使用
codec => json处理JSON日志,避免使用grok二次解析 - 多管道分离:高吞吐的日志流和低吞吐的配置独立管道,避免互相挤占资源
- 监控指标:使用监控API
http://localhost:9600/_node/stats/pipelines查看各管道的吞吐、延迟、队列深度
八、完整实战案例:接入Nginx访问日志
以下是一个完整的多管道配置示例,展示从采集到Elasticsearch索引的全流程:
# /etc/logstash/pipelines.yml
- pipeline.id: nginx-access
path.config: "/etc/logstash/conf.d/nginx-access.conf"
pipeline.workers: 2
queue.type: persisted
queue.max_bytes: 2gbnginx-access.conf
input {
beats {
port => 5044
ssl => true
ssl_certificate => "/etc/logstash/ssl/logstash.crt"
ssl_key => "/etc/logstash/ssl/logstash.key"
}
}
filter {
# 1. grok 解析日志行
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
tag_on_failure => ["_grok_failure"]
remove_tag => ["_grok_failure"] if "_grok_failure" not in [tags]
}
# 2. 解析日期
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
# 3. 地理IP解析
geoip {
source => "clientip"
target => "geo"
database => "/etc/logstash/GeoLite2-City.mmdb"
}
# 4. UserAgent解析
useragent {
source => "agent"
target => "ua"
}
# 5. 字段处理
mutate {
convert => { "response" => "integer" }
convert => { "bytes" => "integer" }
remove_field => ["message", "path", "host", "type"]
}
}
output {
elasticsearch {
hosts => ["https://localhost:9200"]
index => "nginx-access-%{+YYYY.MM.dd}"
user => "logstash_internal"
password => "${ES_PWD}"
ssl => true
cacert => "/etc/logstash/ssl/ca.crt"
ilm_rollover_alias => "nginx-access"
ilm_pattern => "{now/d}-000001"
}
}验证管道配置:
# 配置语法检查
bin/logstash -f /etc/logstash/conf.d/nginx-access.conf --config.test_and_exit
# 输出监控指标
curl -s http://localhost:9600/_node/stats/pipelines/nginx-access?pretty | jq '.pipelines."nginx-access".events'总结
Logstash管道配置虽然概念清晰,但在实际生产中需要根据数据源特征、吞吐量要求、资源限制等多维度进行精细化调优。掌握本文介绍的Input/Filter/Output插件体系和性能调优策略后,你已具备构建企业级日志采集管道的能力。