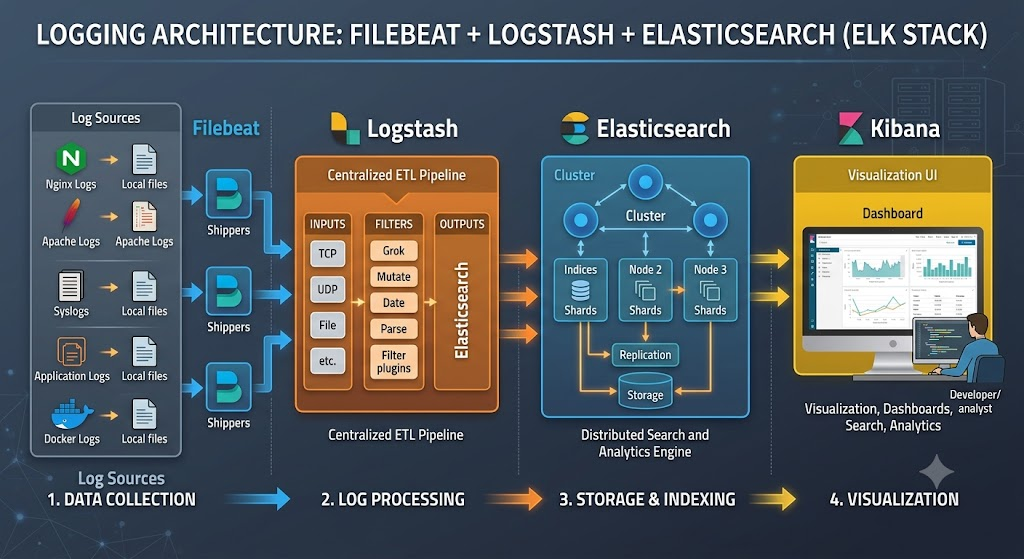
Elasticsearch 集群部署与分片机制详解
Elasticsearch 集群架构
Elasticsearch 天生就是分布式搜索引擎,一个集群由多个节点(Node)组成,每个节点在集群中扮演不同角色。理解节点类型是构建高可用集群的第一步。
Elasticsearch 中的节点按职责分为四种主要类型:
- Master(候选)节点:负责集群范围内的轻量级管理操作,如创建或删除索引、跟踪集群中的节点、决定分片分配到哪个节点。通过
node.roles: [master]配置。建议配置 3 个专用 master 节点以保障高可用。 - Data 节点:负责存储数据、执行与数据相关的 CRUD 操作以及搜索聚合。这是集群的工作主力。通过
node.roles: [data]配置。 - Ingest 节点:在索引数据之前执行预处理管道(Pipeline),例如格式转换、字段提取、数据增强。通过
node.roles: [ingest]配置。 - Coordinating(协调)节点:充当客户端请求的负载均衡器,将搜索请求分发到 data 节点并合并结果。若未明确指定角色则为 coordinating-only 节点,通过
node.roles: []配置。
在生产环境中,建议将角色分离——不要在一个节点上混合 master 和 data 职责。专用 master 节点保障集群稳定性,专用 data 节点保障数据吞吐性能。
分片机制
Elasticsearch 将索引(Index)的水平划分为多个分片(Shard),每个分片本质上是一个完整的 Lucene 索引。
- Primary Shard(主分片):每个文档属于一个主分片。主分片数量在索引创建时确定,创建后不可修改。每个主分片处理写入操作。默认值为 1(7.x 之后)或 5(6.x 及之前)。
- Replica Shard(副本分片):主分片的副本,用于提高查询吞吐量和数据冗余。副本分片数量可以动态调整。默认值为 1,即每个主分片有一个副本。
分片分配策略由 Elasticsearch 内置的分配器(Allocator)决定,核心目标:
- 将分片均匀分布到集群中的 data 节点上,实现负载均衡。
- 保证主分片与其副本分片不在同一节点上,避免单点故障。
- 支持基于磁盘水位的分配决策(low/hood/flood 水位线)。
集群部署配置示例
以下是一个三节点专用 master 集群的 elasticsearch.yml 核心配置示例:
# --- 通用配置 ---
cluster.name: production-logs
node.name: node-1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
# --- 节点角色 ---
# 节点1:专用 master
node.roles: [master]
# 节点2:master + data(小型集群)
# node.roles: [master, data]
# --- 发现与引导 ---
discovery.seed_hosts:
- 10.0.0.11:9300
- 10.0.0.12:9300
- 10.0.0.13:9300
# 仅首次启动时需要
cluster.initial_master_nodes:
- node-1
- node-2
- node-3配置要点说明:
discovery.seed_hosts:设置集群中用于发现的其他节点地址端口。Elasticsearch 使用 Zen Discovery 协议,每个节点通过种子主机列表找到集群中的其他节点。cluster.initial_master_nodes:仅在新集群首次启动时使用。列出参与首次 master 选举的候选节点名称。当集群已运行后将节点加入时,不需要此配置,通过种子发现即可。
水平扩展与故障转移
Elasticsearch 的水平扩展能力是其核心优势:
- 水平扩展:只需向集群添加新的 data 节点,Elasticsearch 自动将分片重新分配到新节点上。无须停止服务或重新索引数据。例如集群从 3 个 data 节点扩展到 6 个 data 节点,吞吐量近似翻倍。
- 故障转移:当 data 节点宕机时,master 节点检测到心跳超时后,将该节点上的主分片提升到其副本所在的节点上成为新的主分片。然后集群重新分配副本分片以恢复到设定的副本数。
- 脑裂预防:通过
discovery.zen.minimum_master_nodes(<=6.8)或 7.x 内置的 fault detection 机制防止集群因网络分区出现脑裂。通常 master 候选节点数应为奇数(推荐 3 个),并设置法定票数。
分片优化建议
错误的分片策略是 Elasticsearch 性能问题的首要来源。以下是经过验证的最佳实践:
- 单个分片大小控制在 10GB~50GB:过小导致过多分片浪费资源,过大导致查询和恢复变慢。以日志场景为例,每天索引约 100GB 数据,设 3~5 个主分片即可。
- 每 GB 堆内存不超过 20 个分片:例如 16GB 堆内存的节点,分片总数(主 + 副本)不超过 320 个。
- 避免过度分片:分片数 = 数据节点数 × 每个节点可承载的分片数。不要盲目多分片,额外的分片增加集群管理开销。
- 使用 ILM(索引生命周期管理):通过
PUT _ilm/policy/设置自动 rollover 策略,让分片大小保持在合理范围。 - 合理配置副本数:对于日志等可丢失的数据,
index.number_of_replicas: 1即可;对于关键业务数据可设为 2。 - 分片分配感知:通过
cluster.routing.allocation.awareness.attributes实现跨机架/可用区的分片分布,避免同一索引所有副本位于同一故障域。
集群健康状态监控
Elasticsearch 提供了多层次的健康监控机制:
- 集群健康 API:
GET _cluster/health返回三种状态——green(所有主分片和副本分片正常)、yellow(主分片正常但副本分片未完全分配)、red(主分片未分配,数据不可用)。 - 节点统计 API:
GET _nodes/stats和GET _cat/nodes?v用于查看每个节点的 CPU、内存、磁盘 I/O、GC 情况。 - 索引统计 API:
GET _cat/indices?v和GET _stats查看文档数量、存储大小、搜索/索引速率。 - 热点线程(Hot Threads):
GET _nodes/hot_threads定位 CPU 突发或阻塞线程。 - 磁盘水位:通过
GET _cat/allocation?v查看各节点磁盘使用情况,结合cluster.routing.allocation.disk.watermark.low(默认 85%)和flood_stage(默认 95%)触发自动分片迁移。
推荐搭配 Elastic Stack 的监控组件(Metricbeat + Kibana Stack Monitoring)实现集群的可视化监控面板,实时追踪集群健康、搜索延迟和资源使用趋势。
通过以上架构设计、合理分片配置和持续监控,Elasticsearch 集群可以在 PB 级别的数据规模下保持稳定高效运行。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。