ELK Stack 入门教程:Elasticsearch、Logstash、Kibana 三件套详解
ELK Stack 入门教程:Elasticsearch、Logstash、Kibana 三件套详解
在现代 IT 运维与开发中,日志数据的管理与分析是确保系统稳定性和可观测性的核心环节。ELK Stack 作为业界最流行的开源日志管理解决方案,由 Elasticsearch、Logstash 和 Kibana 三大核心组件组成。本文将带你从零开始,全面了解 ELK Stack 的架构原理、各组件功能、版本兼容性及适用场景。
一、ELK Stack 整体介绍
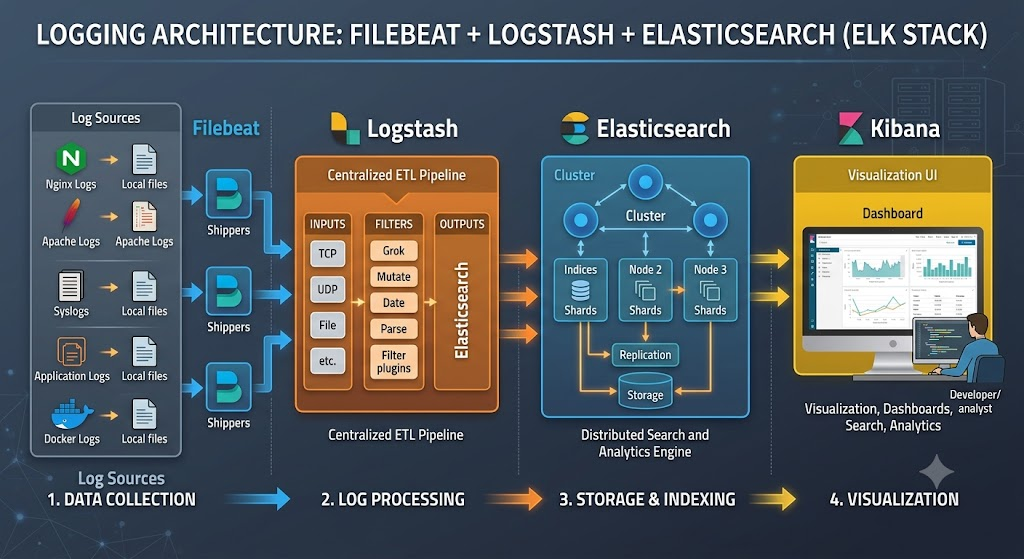
ELK Stack 是一个端到端的日志收集、存储、搜索与可视化平台。它通过三个专精组件协同工作,将原始日志数据转化为可交互、可检索的结构化信息。
- Elasticsearch:分布式搜索与分析引擎,负责存储、索引和搜索日志数据,基于 Lucene 构建,提供近实时的全文检索能力。
- Logstash:服务器端数据处理管道,负责从多种来源采集数据,进行解析、过滤、转换,然后将数据发送到 Elasticsearch 或其他存储后端。
- Kibana:数据可视化与 Web 管理界面,为用户提供仪表盘、图表、地图等可视化工具,以及通过 Discover 模块对 Elasticsearch 中的数据进行自由探索。
三者组合形成一个完整的数据链路:数据源 → Logstash(采集/处理)→ Elasticsearch(存储/索引)→ Kibana(展示/分析)。此外,后期的 Beats(轻量级采集器)也常被纳入体系,形成 Elastic Stack。
二、Elasticsearch 详解
Elasticsearch 是 ELK Stack 的核心存储与检索引擎,基于 Apache Lucene 构建,具备高可用、高扩展性,支持 PB 级数据的近实时搜索。
2.1 分布式搜索引擎
Elasticsearch 天然支持分布式架构。一个集群由多个节点(Node)组成,每个节点可运行在同一台或不同服务器上。数据被划分为分片(Shard),每个分片是一个独立的 Lucene 索引,分片可分布在不同的节点上,同时每个分片有对应的副本(Replica) 提供容错和查询负载均衡。
# 查看集群健康状态
curl -X GET "localhost:9200/_cluster/health?pretty"通过 REST API 进行索引创建、文档写入与搜索操作,完全基于 HTTP/JSON 协议,语言无关,易于集成。
2.2 倒排索引
Elasticsearch 实现快速全文检索的核心数据结构是倒排索引(Inverted Index)。与传统正向索引(文档→关键词)不同,倒排索引以词项(Term) 为键,记录该词项出现在哪些文档中,实现 O(1) 级别的查找效率。
- 分词(Tokenization):将文本切分成词项。
- 归一化(Normalization):转小写、去除停用词、词干提取等。
- 构建索引:建立词项到文档 ID 的映射,并记录位置信息。
# 示例:创建索引并指定分词器
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "standard"
}
}
}
}
}2.3 REST API 操作
Elasticsearch 提供丰富 RESTful API,覆盖索引管理、文档 CRUD、搜索聚合、集群监控等操作。
# 插入文档
POST /logs/_doc
{
"@timestamp": "2025-06-08T10:00:00",
"level": "ERROR",
"message": "Connection timeout to database"
}
# 全文搜索
GET /logs/_search
{
"query": {
"match": {
"message": "timeout"
}
}
}三、Logstash 详解
Logstash 是一个具备实时管道能力的数据处理引擎,采用插件化架构,通过 input → filter → output 三个阶段对数据进行采集、转换和输出。
3.1 数据采集:Input 插件
Input 插件负责从各种数据源读取数据。常用的 Input 插件包括:
- file:从文件尾部实时读取(类似 tail -f)。
- beats:接收来自 Filebeat、Metricbeat 等 Beats 采集器的数据。
- tcp/udp:通过 TCP 或 UDP 协议接收数据。
- kafka:从 Kafka 主题中消费日志数据。
- http:以 HTTP 服务端方式接收 POST 请求数据。
input {
file {
path => "/var/log/nginx/access.log"
start_position => "beginning"
type => "nginx-access"
}
}3.2 管道处理:Filter 插件
Filter 插件是 Logstash 的核心价值所在,它负责对原始数据进行解析、结构化和清洗。
- grok:将非结构化文本解析为结构化字段,是最常用的 filter。
- mutate:对字段进行重命名、删除、类型转换等操作。
- date:解析时间戳字段并将日期标准化。
- json:将 JSON 字符串解析为结构化数据。
- geoip:根据 IP 地址添加地理位置信息。
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
}
geoip {
source => "clientip"
}
}3.3 数据输出:Output 插件
处理完成的数据通过 Output 插件发送到目标系统。
- elasticsearch:写入 Elasticsearch 索引(最常用)。
- stdout:输出到控制台,便于调试。
- kafka:写入 Kafka 作为缓冲层。
- file:写入到本地文件。
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "nginx-logs-%{+YYYY.MM.dd}"
}
stdout { codec => rubydebug }
}完整的 Logstash 配置文件示例如下:
input { file { path => "/var/log/syslog" type => "syslog" } }
filter { grok { match => { "message" => "%{SYSLOGBASE}" } } }
output { elasticsearch { hosts => ["localhost:9200"] } }四、Kibana 详解
Kibana 是 ELK Stack 的可视化门户,通过浏览器提供对 Elasticsearch 数据的实时查询、图表绘制和仪表盘管理。
4.1 Discover:数据探索
Discover 模块提供类似搜索引擎的交互式查询界面,用户输入 Kibana Query Language(KQL) 或 Lucene 语法即可实时搜索数据。支持时间范围过滤器、字段筛选和保存搜索条件。
# KQL 查询示例
level: ERROR AND message: "timeout"
# 等价于 Elasticsearch query DSL 中的布尔查询4.2 可视化与仪表盘
Kibana 提供丰富的可视化类型:
- 柱状图/折线图:展示时间序列趋势。
- 饼图/圆环图:展示分类占比。
- 数据表:以表格形式展示聚合结果。
- 地图:基于 GeoIP 数据的地理信息可视化。
- 度量(Metric):展示单一数值指标。
创建好单个可视化后,可将其组合到仪表盘(Dashboard)中,统一监控多个维度的指标。仪表盘支持自动刷新、全屏模式、嵌入外部页面等特性,是运维监控中心的理想载体。
4.3 管理功能
Kibana 的 Stack Management 提供:索引模式管理、已保存对象导入导出、用户和角色权限控制(需 X-Pack)、告警规则配置等功能。
五、各组件版本兼容性说明
ELK Stack 的三个组件必须使用相同的主版本号才能保证兼容性。混合使用不同主版本可能导致数据发送失败或功能异常。
# 推荐版本对齐原则
Elasticsearch 7.x ←→ Logstash 7.x ←→ Kibana 7.x
Elasticsearch 8.x ←→ Logstash 8.x ←→ Kibana 8.x- 次版本号:建议保持一致,但通常允许跨次版本(如 8.8 + 8.12),不过不保证所有新功能可用。
- Java 环境:Elasticsearch 7.x 内置了 Java 运行时;8.x 要求 JDK 17+。
- 操作系统支持:各组件均支持 Linux、macOS 和 Windows,生产环境推荐 Linux。
- Beats 兼容性:Beats 采集器与 Elasticsearch 主版本需对应,且需注意 TLS/安全配置的一致性。
部署前请务必查阅官方 Elastic Stack Compatibility Matrix,以获取最新的版本兼容对照表。
六、适用场景总结
ELK Stack 广泛应用于以下场景:
- 集中式日志管理:将分散在多台服务器上的应用日志、系统日志、安全日志统一采集到一个平台,实现集中检索与告警。
- 运维监控与排障:监控 Nginx/Apache 访问日志、数据库慢查询日志,快速定位错误原因,辅助根因分析。
- 安全分析与 SIEM:ELK 可构建基础级别的安全信息和事件管理(SIEM)系统,分析认证失败、异常访问等安全事件。
- 业务数据分析:分析用户行为日志、点击流数据,生成业务报表与用户画像。
- APM 与性能分析:结合 Elastic APM 模块,追踪应用性能,分析接口响应时间、事务链路。
ELK Stack 凭借其开箱即用、插件丰富和强大的搜索能力,已成为当今可观测性领域的基石工具。掌握 ELK Stack,不仅是运维工程师的核心技能,也是后端开发和 SRE 工程师的必备素养。